IT Recruiting
The Future of Hiring: Insights from a Machine Learning Recruitment Agency
The AI revolution has fundamentally shifted the hiring landscape, and nowhere is this more evident than in machine learning recruitment. As a specialized machine learning recruitment agency, we’ve witnessed firsthand how traditional hiring approaches fall short when sourcing ML talent. The reality in today’s tech landscape is that finding qualified machine learning engineers requires a completely different strategy than conventional tech recruitment.
The Evolution of ML Talent Acquisition
What we’re seeing with current machine learning recruitment trends reveals a critical gap between what companies think they need and what the market actually offers. The demand for ML engineers has grown 344% over the past three years, yet most organizations still approach hiring with outdated job descriptions that focus on generic “data science” skills rather than the specific technical competencies required for production ML systems.
The field has evolved dramatically from the early “A/B divide in data science”—where analysts built models and engineers deployed them—into highly specialized roles. Modern machine learning staffing requires understanding that ML engineering now encompasses backend software engineering, machine learning algorithms, and analytics/statistics in a unified discipline.
Here’s what most companies miss about machine learning recruitment: the role has evolved far beyond building models in Jupyter notebooks. Today’s ML engineers need expertise in building complete ML platforms—systematic, automated ways to take raw data, transform it, learn models from it, and show results that support decision-making. A candidate who can build an impressive neural network from scratch might struggle with feature stores, model registries, or data drift monitoring—skills that are now non-negotiable for production ML systems.
Technical Depth: Beyond the Resume Keywords
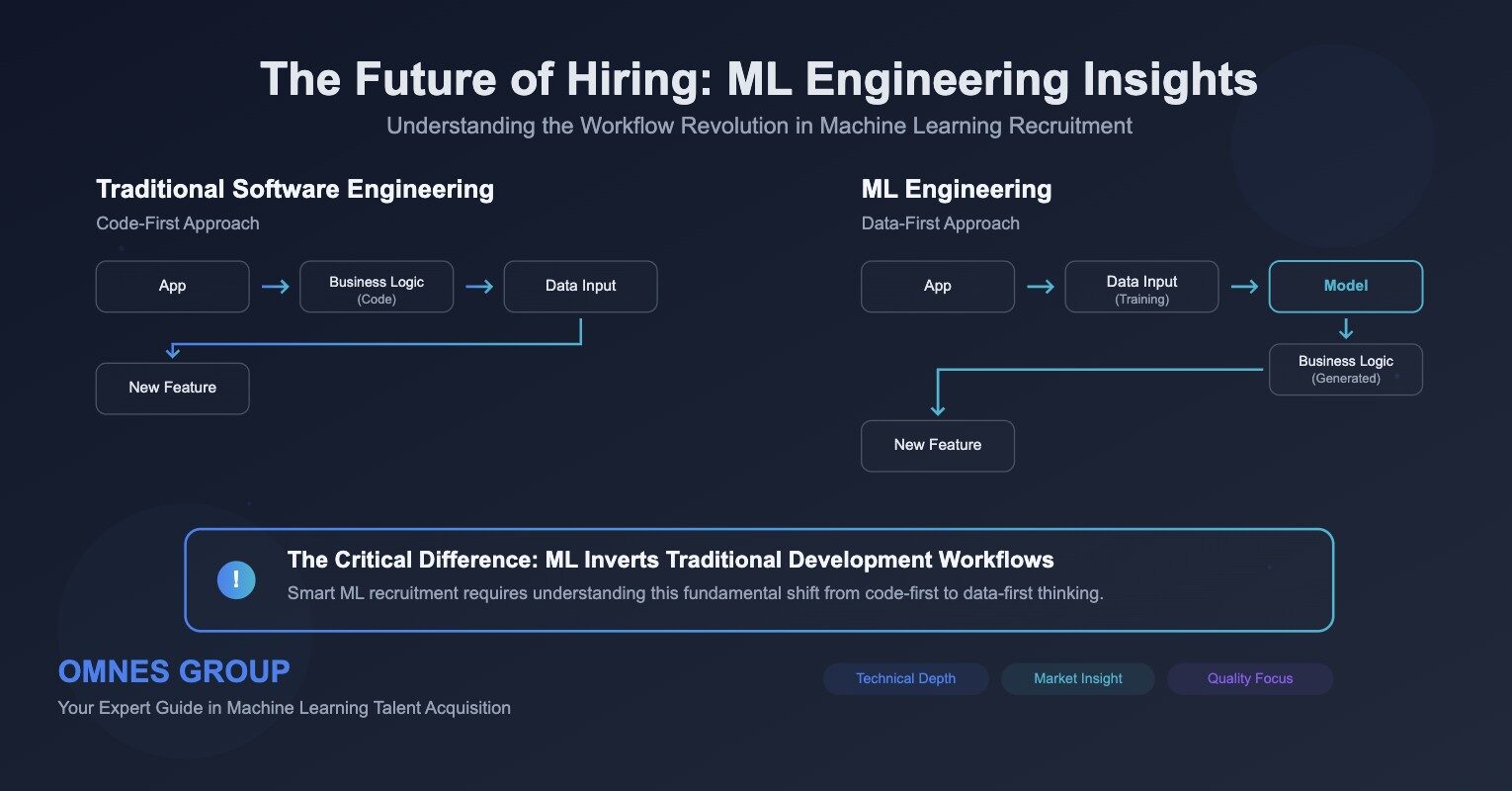
Given the current market shift toward production-ready AI systems, AI staffing solutions must evaluate candidates on practical implementation skills rather than academic credentials alone. We’ve moved beyond resume screening to evaluating how candidates understand the fundamental difference between traditional software development and ML development workflows.
Traditional software engineering follows a predictable pattern: take existing data, add business logic through code, and integrate new features. Machine learning inverts this completely. Instead of coding business logic, ML engineers use input data to build models that generate the business logic as output data.
This workflow inversion means successful ML candidates need a completely different mindset and skill set:
Core ML Platform Components We Assess:
Foundational Engineering Skills:
- Git, SQL, and bash scripting—the “table stakes” for ML work that enable productivity from day one
- Understanding of serialization formats: Protobuf, Avro, Parquet, and JSON for efficient data handling
- Command-line proficiency with tools like awk, grep, cut, and jq for data examination and processing
- Docker containerization and Kubernetes orchestration for model deployment at scale
Data Infrastructure & Pipeline Engineering:
- Java/Scala expertise for heavy-duty data processing with frameworks like Kafka and Flink
- Real-time streaming architecture experience with Apache Kafka for ML data pipelines
- Search and indexing capabilities with Elasticsearch or OpenSearch for large-volume data queries
- Understanding of data serialization trade-offs and performance implications for ML workloads
Model Development & Experimentation:
- Python ecosystem mastery: Pandas, Jupyter Notebooks, scikit-learn, XGBoost for traditional ML tasks
- Deep learning frameworks: PyTorch and TensorFlow for neural network development
- Statistical computing with R or Julia for specialized analysis requirements
- Feature engineering and exploratory data analysis (EDA) capabilities for model preparation
Production ML Operations:
- Web service development in Python (FastAPI), Go, or Java for model serving
- Model versioning and artifact management systems
- Concept drift detection and model performance monitoring
- Cross-functional collaboration skills for working with product, SRE, and data engineering teams
Cloud & Infrastructure:
- Public cloud ML platforms: AWS SageMaker, Google Vertex AI, Azure ML
- Container orchestration and distributed systems management
- Monitoring and alerting with tools like Grafana, DataDog, and Prometheus
- Understanding of SLA requirements for low-latency model serving
The reality that many hiring managers miss: successful ML engineers spend most of their time on data cleaning, pipeline engineering, and system integration—not building cutting-edge models. We evaluate candidates on their understanding of this operational reality.
The Remote Work Impact on ML Recruitment
Remote-first culture has changed how we evaluate collaboration skills in ML engineers. The traditional approach of hiring individual contributors who work in isolation no longer aligns with how modern ML teams operate. Today’s machine learning recruitment process must assess candidates’ ability to collaborate asynchronously on complex technical problems.
What this means for your hiring strategy: look for engineers who can document their model decisions, communicate technical trade-offs clearly, and contribute to shared codebases using tools like DVC (Data Version Control) and MLflow for experiment tracking.
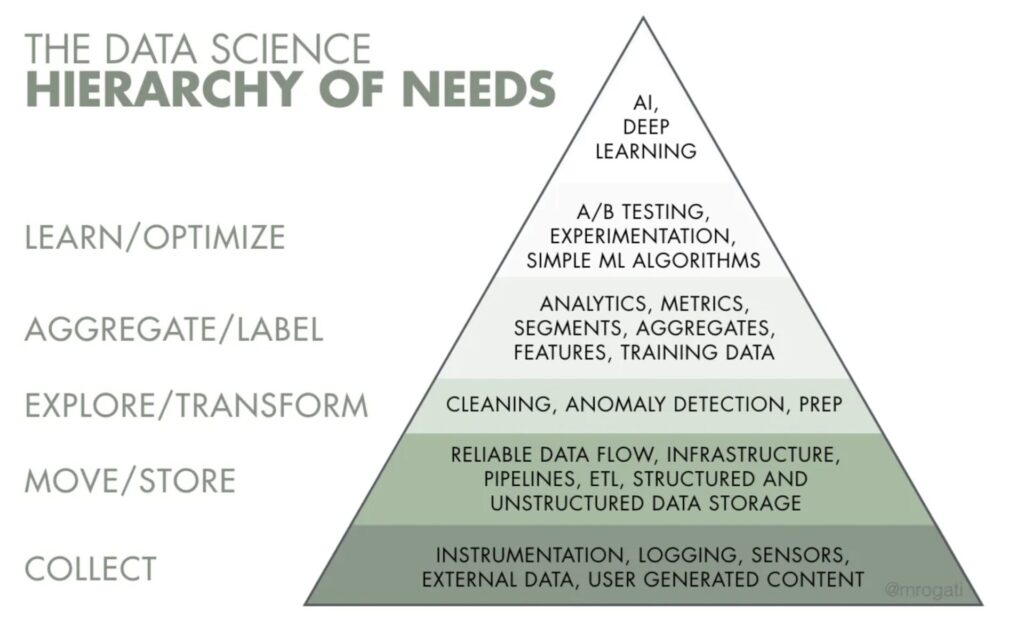
The Reality Check: ML Hierarchy of Needs
Before companies can successfully deploy ML models, they need solid foundations:
Let’s rethink how you approach ML hiring by understanding where most companies actually are in their ML journey. The data science hierarchy of needs reveals that AI and deep learning—the technologies generating headlines—represent only the tip of the iceberg.
Instrumentation and Data Collection: Your applications must be set up to collect the specific data needed for ML, including proper logging of fields that will become model features.
Data Infrastructure: Centralized data flows via Extract, Transform, Load (ETL) processes, with robust pipelines for analysis, cleaning, and feature creation.
Analytics and Exploration: Good analysis environments where ML engineers can explore data before building production models.
Traditional ML Models: Success with tabular data and simple heuristics before advancing to complex deep learning approaches.
Monica Rogati
This hierarchy explains why specialized machine learning recruitment requires evaluating candidates across the full spectrum of ML infrastructure, not just model-building capabilities. The most valuable ML engineers understand that the heart of successful projects is good, clean data that’s collected, analyzed, and prepared consistently.
Here’s the market reality most companies overlook: deep learning makes up only 5-7% of industry ML work. The majority of production ML systems rely on traditional machine learning approaches built on solid data foundations.
Understanding ML’s Technical Debt Challenge
Machine learning systems carry what Google researchers call “technical debt at the system level.” Unlike traditional software where you can test deterministic outcomes, ML systems are inherently non-deterministic. You cannot guarantee the same result every time, and with deep learning models, you often cannot reverse-engineer the features that led to specific outputs.
This creates unique operational challenges that machine learning recruitment agencies must account for:
Silent Failures: ML systems can fail in ways that aren’t immediately obvious. Data drift, seasonality effects, or malformed log data can cause models to degrade performance without triggering traditional error alerts.
Maintenance Complexity: ML systems require ongoing maintenance of both models and the data pipelines that feed them. Changes in upstream data sources can break models in subtle ways.
Metadata Management: Production ML systems need sophisticated tooling to track model versions, feature definitions, training data lineage, and performance metrics over time.
When evaluating ML candidates, we assess their understanding of these operational realities, not just their ability to achieve high accuracy scores in notebook environments.
AI Staffing Solutions: Quality Over Quantity
While most recruitment focuses on keyword matching, we’ve built our process around understanding actual project needs and the complete ML development lifecycle. The traditional approach of sending 20 CVs hoping one sticks doesn’t work in today’s competitive tech recruitment services market, especially when ML projects require such diverse technical competencies.
Based on our experience with similar roles, successful ML hiring requires evaluating candidates who understand that ML development fundamentally inverts traditional software engineering workflows. Instead of writing business logic in code, ML engineers build systems that learn business logic from data.
Comprehensive Technical Assessment
We don’t just verify that candidates know TensorFlow—we assess whether they understand when traditional tabular ML approaches might outperform deep learning for specific use cases. Can they explain the trade-offs between different model architectures based on your data characteristics and latency requirements? Do they understand the operational implications of their technical choices?
Real-World Problem Solving
Rather than whiteboard coding exercises, we evaluate candidates on realistic ML scenarios: designing feature stores for consistent model serving, implementing data drift detection systems, or architecting ML platforms that can handle both batch training and real-time inference.
Operational Maturity Assessment
We assess candidates’ understanding of ML’s unique operational challenges. Can they design systems that gracefully handle the non-deterministic nature of ML? Do they understand how to monitor and maintain models in production, where silent failures and data drift can degrade performance without obvious error signals?
Cultural Fit for ML Teams
Machine learning development is inherently experimental and iterative, requiring a different mindset from traditional software engineering. We assess candidates’ comfort with uncertainty, their approach to hypothesis-driven development, and their ability to communicate technical concepts to non-technical stakeholders.
Successful ML engineers spend their days on activities that many traditional software engineers find unfamiliar:
Data-Centric Problem Solving:
- Cleaning and preparing data for modeling—often 60-80% of the actual work
- Running, re-running, and evaluating models until statistical results make sense
- Understanding upstream and downstream data flows across complex distributed systems
- Debugging “silent failures” where models degrade performance without obvious error signals
Cross-Functional Collaboration: ML engineers rarely work in isolation. They collaborate extensively with:
- Product managers to define ML feature requirements based on user needs and business metrics
- Data engineers for infrastructure that scales data processing and model training
- Site reliability engineers for container orchestration, monitoring systems, and distributed infrastructure
- UX researchers and data scientists to analyze how users interact with ML-powered features
Systems Thinking: Understanding how multiple models interact within production systems, tracking which models are running where, and predicting impact when system variables change. This systems perspective is crucial for ML engineers who often work across multiple projects simultaneously.
We evaluate candidates on their comfort with this collaborative, experimental, and systems-oriented work environment—not just their ability to implement algorithms.
Data Engineer Recruitment: The Foundation of ML Success
Let’s rethink how you approach data engineer recruitment within your ML hiring strategy. The reality is that without robust data infrastructure, even the most talented ML engineers can’t deliver production value. Your ML initiatives are only as strong as the data pipelines that feed them.
One experienced ML engineer put it perfectly: “The easiest way to get into ML is to be willing to do data engineering.” This insight reveals why so many successful ML careers start with data engineering foundations.
Modern data engineers for ML teams need experience with:
- Real-time stream processing using Apache Kafka or Apache Flink for handling continuous data flows
- Data serialization and storage optimization with formats like Parquet for analytical workloads
- Command-line data processing tools (awk, grep, cut, jq) for examining and debugging data pipelines
- Java or Scala expertise for working with “heavy duty” data processing frameworks at scale
- Integration with ML training and inference workflows, understanding both batch and streaming requirements
Understanding Tool Selection by Project Complexity
Smart machine learning recruitment requires understanding that tool choices depend heavily on data volume and model complexity. Here’s how experienced ML engineers think about this:
Traditional Data Modeling (Linear regression, decision trees, XGBoost):
- Languages: R, Julia, or Python with scikit-learn
- Suitable for: Most business problems that don’t require deep learning complexity
- Data volumes: Up to 10-50GB that can fit on single machines
Small to Medium Models:
- Python ecosystem: Pandas, Jupyter notebooks, scikit-learn for experimentation
- Cloud platforms: AWS SageMaker, Google Vertex AI for managed training and deployment
- Focus: Quick iteration and business value delivery over cutting-edge techniques
Large-Scale Models:
- Distributed computing: Apache Spark when data doesn’t fit on single machines
- Deep learning: PyTorch or TensorFlow for neural network approaches
- Infrastructure: Kubernetes orchestration for model serving at scale
- Specialized platforms: Hugging Face for pre-trained model fine-tuning
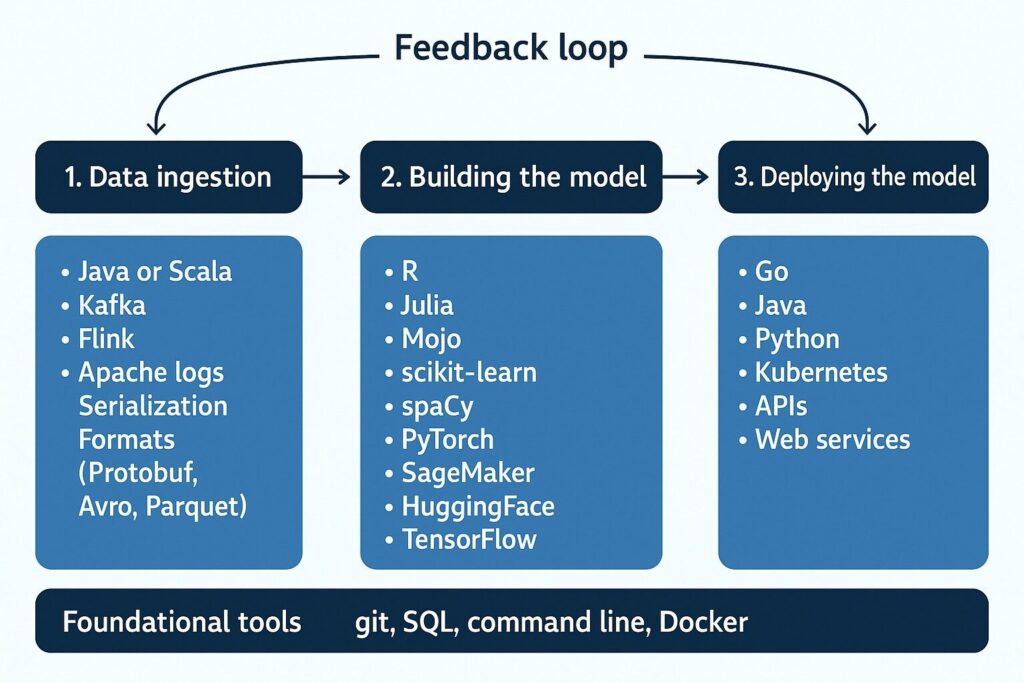
The key insight for hiring: most production ML work involves traditional approaches rather than cutting-edge deep learning. Prioritize candidates who understand this landscape and can select appropriate tools for business requirements.
Career Pathways: Diverse Routes into ML Success
Understanding how professionals transition into machine learning roles is crucial for machine learning recruitment agencies. The field’s rapid evolution means there are multiple successful pathways, each bringing different strengths to ML teams.
The Software Engineering Path
The most common entry route comes from backend software engineering, data engineering, or site reliability engineering backgrounds. These candidates bring essential engineering fundamentals: git, SQL, command-line proficiency, and distributed systems experience. They understand production deployment, monitoring, and the operational aspects that keep ML systems running reliably.
What makes this path successful: ML systems are fundamentally engineering systems with statistical components. Candidates with strong engineering foundations can learn the ML-specific components more easily than data scientists can learn production engineering.
The Data Analysis Path
Some of the most effective ML engineers come from data analyst backgrounds, transitioning through data science roles. These professionals understand data quality issues, statistical modeling, and business context for ML applications. They’ve experienced the frustration of models that don’t translate to production and understand the importance of operational ML infrastructure.
This background is particularly valuable for ML platform roles where understanding diverse data sources and modeling requirements is crucial for building systems that serve multiple teams.
The Academic Research Path
PhD-level researchers bring deep theoretical knowledge but often need support transitioning to production environments. These candidates excel at complex modeling challenges and staying current with academic advances, but may need guidance on engineering practices, distributed systems, and production deployment.
What This Means for Your Hiring Strategy
Rather than requiring specific educational backgrounds, focus on evaluating how candidates’ diverse experiences align with your specific needs:
For Early-Stage ML Initiatives: Prioritize candidates with strong engineering backgrounds who can build reliable foundational systems. As one experienced ML engineer noted, “one of the best skills to learn for getting into the field is engineering basics: git, sql, and cli. These will take you a long way.”
For Established ML Teams: Look for diverse backgrounds that complement existing capabilities. Data analysts who understand business context, researchers who can explore new approaches, and engineers who can scale systems all contribute differently to team success.
For ML Platform Roles: Seek candidates with broad exposure to different ML use cases and the systems thinking to build tools that serve multiple teams effectively.
The key insight: successful ML teams combine different professional backgrounds rather than hiring only one type of candidate. This diversity of perspectives leads to more robust, practical ML systems that deliver real business value.
ML Recruitment Agencies: Specialization Makes the Difference
The challenge with general machine learning recruitment agencies is that they often treat ML hiring like traditional software engineering recruitment. This approach misses the unique aspects of ML roles: the experimental nature of the work, the importance of statistical thinking, and the need for strong communication skills to explain model decisions to business stakeholders.
Here’s what sets specialized ML recruitment apart:
Industry-Specific Expertise
We understand the differences between ML roles across industries. Healthcare ML engineers need different skills than those working in autonomous vehicles or financial services. Your recommendation system engineer should have experience with collaborative filtering and content-based algorithms, not just general deep learning knowledge.
Technical Stack Alignment
We map candidates’ experience to your specific technology requirements. If you’re using Apache Airflow for ML pipeline orchestration, we prioritize candidates with hands-on Airflow experience over those familiar with other workflow tools.
Growth Trajectory Assessment
Machine learning is evolving rapidly. We evaluate candidates’ ability to adapt to new tools and methodologies, their engagement with the ML community, and their track record of staying current with technical advances.
Building Long-Term ML Teams: Understanding Role Specialization
The most successful ML organizations don’t just hire individual contributors—they build cohesive teams that understand the full ML development lifecycle. This requires understanding how the field has evolved from the early “A/B divide” into today’s specialized roles.
Modern ML teams need complementary expertise across the complete ML platform stack:
Machine Learning Engineers: Focus on the complete model lifecycle, from prototyping to production deployment. They bridge the gap between data science and software engineering, handling everything from feature engineering to model serving.
Data Engineers: Build and maintain the data pipelines that are the foundation of any ML system. They handle ETL processes, data quality monitoring, and ensure the reliable data flows that ML models depend on.
MLOps Engineers: Specialize in the operational aspects of ML systems, including model deployment, monitoring, infrastructure management, and the unique challenges of maintaining non-deterministic systems in production.
Analytics Engineers: Work between data engineering and analysis, focusing on transforming raw data into analysis-ready datasets and maintaining the data models that feed both reporting and ML systems.
Applied Researchers: Explore new ML approaches and stay current with academic developments, translating research insights into practical applications for production systems.
A strategic machine learning recruitment approach considers how each hire contributes to your position in the data science hierarchy of needs. Are you still building foundational data infrastructure, or are you ready for advanced ML applications? The answer determines which specializations you need to prioritize.
The key insight from successful ML organizations: most value comes from solving the foundational data and infrastructure challenges, not from implementing the latest deep learning architectures. Focus your hiring on candidates who understand this reality and can build robust, maintainable ML systems.
The Future of ML Hiring: Beyond the Deep Learning Hype
As AI continues to reshape every industry, it’s crucial to understand that the most visible advances—like ChatGPT and generative AI—represent only a small fraction of real-world ML applications. Deep learning makes up just 5-7% of industry ML work, yet media coverage often suggests it’s the entire field.
Smart machine learning recruitment strategies focus on the 93-95% of ML work that involves building robust, scalable systems for traditional machine learning applications: recommendation engines, fraud detection, demand forecasting, and optimization problems that drive real business value.
Emerging Specializations We’re Tracking:
ML Platform Engineers: Specialists in building internal ML platforms that make it easy for teams to move from prototype to production, handling the complex infrastructure requirements that most companies underestimate.
LLM Integration Engineers: Not deep learning researchers, but engineers who understand how to integrate large language models into existing products and workflows, handling API management, prompt engineering, and cost optimization.
ML Reliability Engineers: Focused on the operational challenges unique to ML systems, including data drift detection, model performance monitoring, and managing the technical debt inherent in ML platforms.
Edge ML Engineers: Optimizing traditional ML models for deployment on mobile and IoT devices, where latency and resource constraints matter more than state-of-the-art accuracy.
The organizations building sustainable competitive advantages aren’t chasing the latest deep learning trends—they’re investing in the foundational capabilities that make ML systems reliable, scalable, and maintainable over time.
What This Means for Your Hiring Strategy
Instead of competing for the small pool of deep learning experts, focus on finding engineers who understand ML systems holistically. The most valuable candidates are those who can build and maintain the infrastructure that makes ML reliable and scalable, regardless of whether the models involved are simple linear regression or complex neural networks.
When evaluating ML candidates, consider their experience with:
End-to-End Project Experience: Look for candidates who have built complete ML applications, from data ingestion through production deployment. This demonstrates understanding of the full ML lifecycle rather than isolated skills.
Open Source Contributions: Active contributors to projects like PyTorch, scikit-learn, or Apache Airflow demonstrate technical depth and community engagement. These candidates often understand tooling limitations and best practices better than those who only use these tools.
Real-World Business Applications: Candidates with experience building systems like recommendation engines, fraud detection, or demand forecasting understand the practical challenges of translating business requirements into ML solutions.
Cross-Functional Collaboration: Since ML engineers work closely with product managers, data engineers, and SRE teams, evaluate communication skills and experience working in collaborative environments.
The most successful ML hires understand that machine learning is fundamentally an engineering discipline with statistical components, not pure research. They focus on building reliable systems that deliver consistent business value rather than chasing academic benchmarks or implementing the latest research papers.
Partnering for ML Hiring Success
Navigate the evolving ML talent landscape with expert guidance that combines deep technical insight with strategic hiring collaboration. The complexity of modern ML roles requires a specialized approach that goes beyond traditional recruitment methods.
Rather than competing with dozens of other companies for the same visible candidates, let’s discuss how to identify and attract ML talent that aligns with your specific technical requirements and company culture.
The future of your AI initiatives depends on building the right team today. Ready to rethink your approach to machine learning recruitment? Contact our team to discuss your machine learning staffing needs and discover how specialized technical recruitment can accelerate your AI initiatives.